Syne Tune: Large-Scale and Reproducible Hyperparameter Optimization



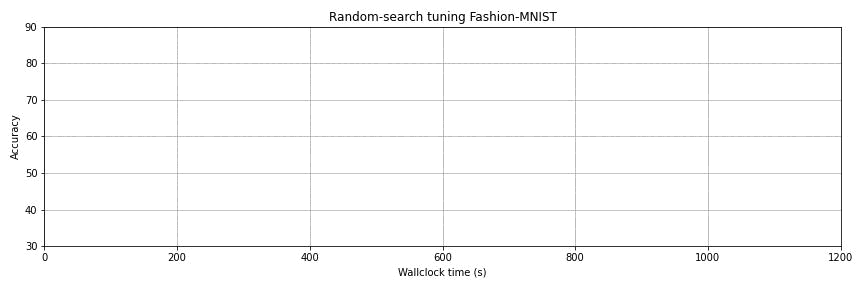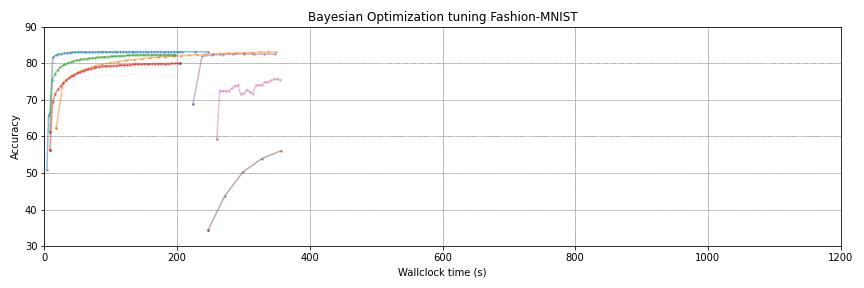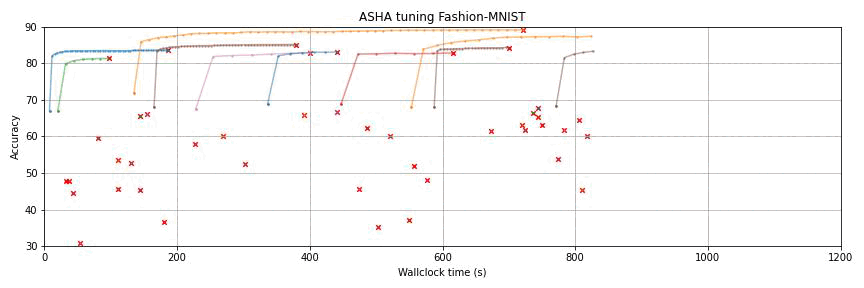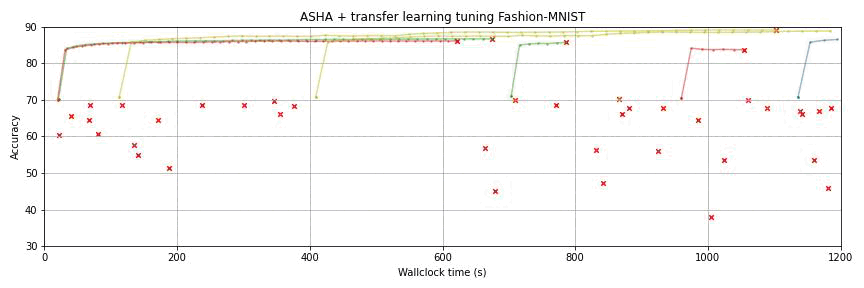
This package provides state-of-the-art algorithms for hyperparameter optimization (HPO) with the following key features:
Wide coverage (>20) of different HPO methods, including:
Asynchronous versions to maximize utilization and distributed versions (i.e., with multiple workers);
Multi-fidelity methods supporting model-based decisions (BOHB, MOBSTER, Hyper-Tune, DyHPO, BORE);
Hyperparameter transfer learning to speed up (repeated) tuning jobs;
Multi-objective optimizers that can tune multiple objectives simultaneously (such as accuracy and latency).
HPO can be run in different environments (locally, simulation) by changing just one line of code.
Out-of-the-box tabulated benchmarks that allows you simulate results in seconds while preserving the real dynamics of asynchronous or synchronous HPO with any number of workers.
Getting Started
Next Steps
Tutorials